




TL;DR
Amazon's redshift service makes life easier for analytics processes without managing Data Warehouse. We can use it for real-time processing and prediction of data.
Redshift is just a flavor of PostgreSQL.
The idea behind this article is to how to create a cluster and get started with it using Console.
Login into the AWS console and go to the redshift console and click on create.
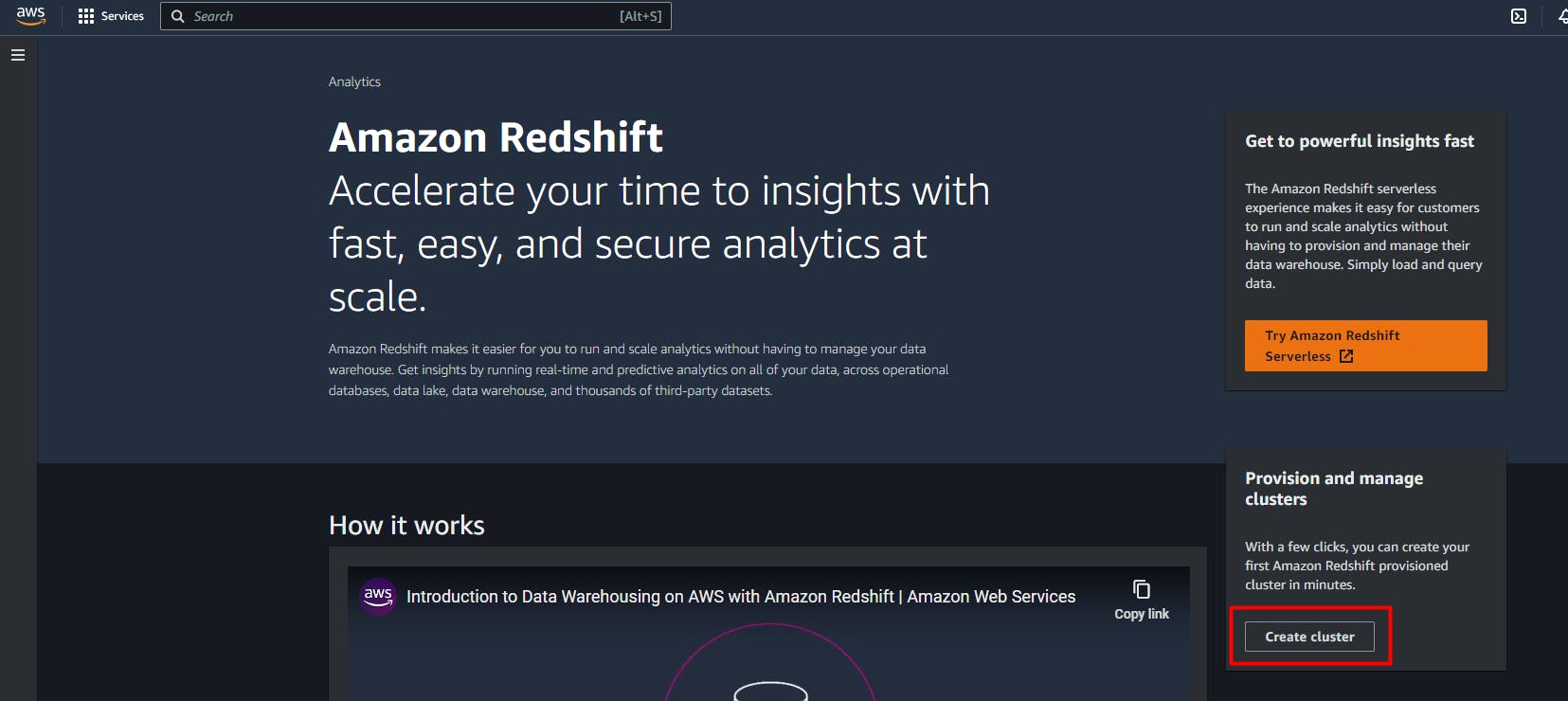
follow the below snapshot to create it,
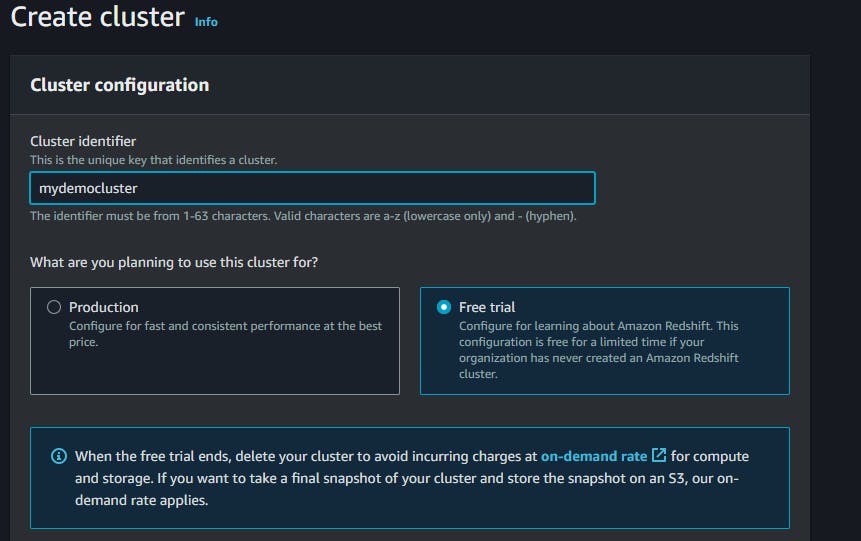
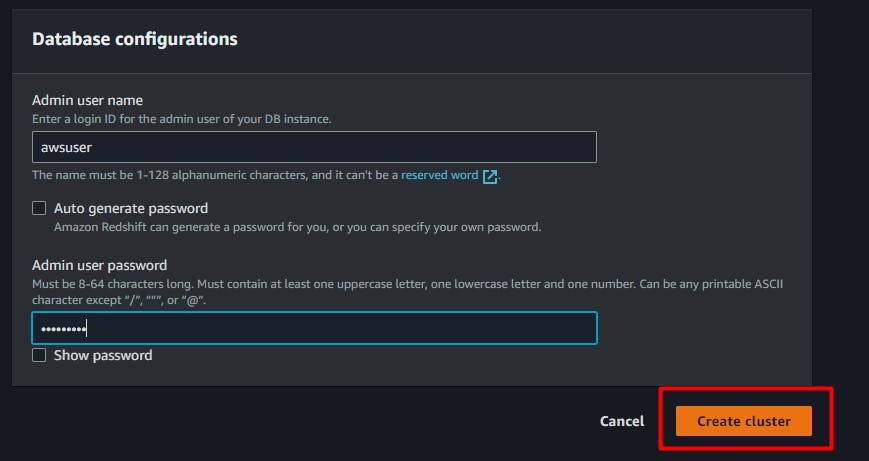
we can choose our username and password also.
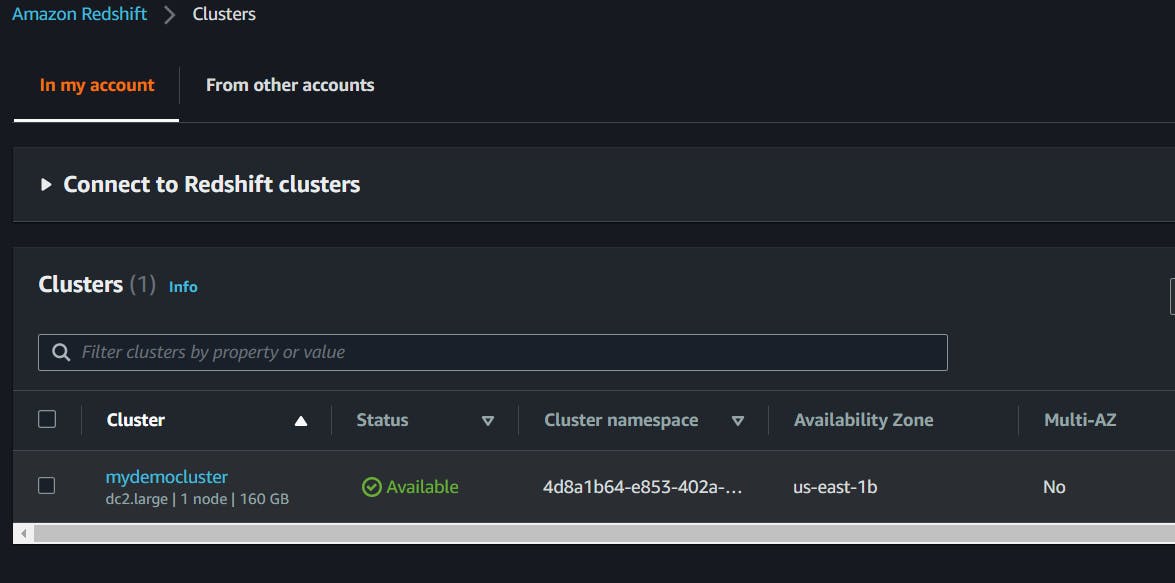
its created now,
Use of query editor to connect the cluster, follow steps,

you can also select the first one instead of query editor v2.
if select the default version you got a view like below,
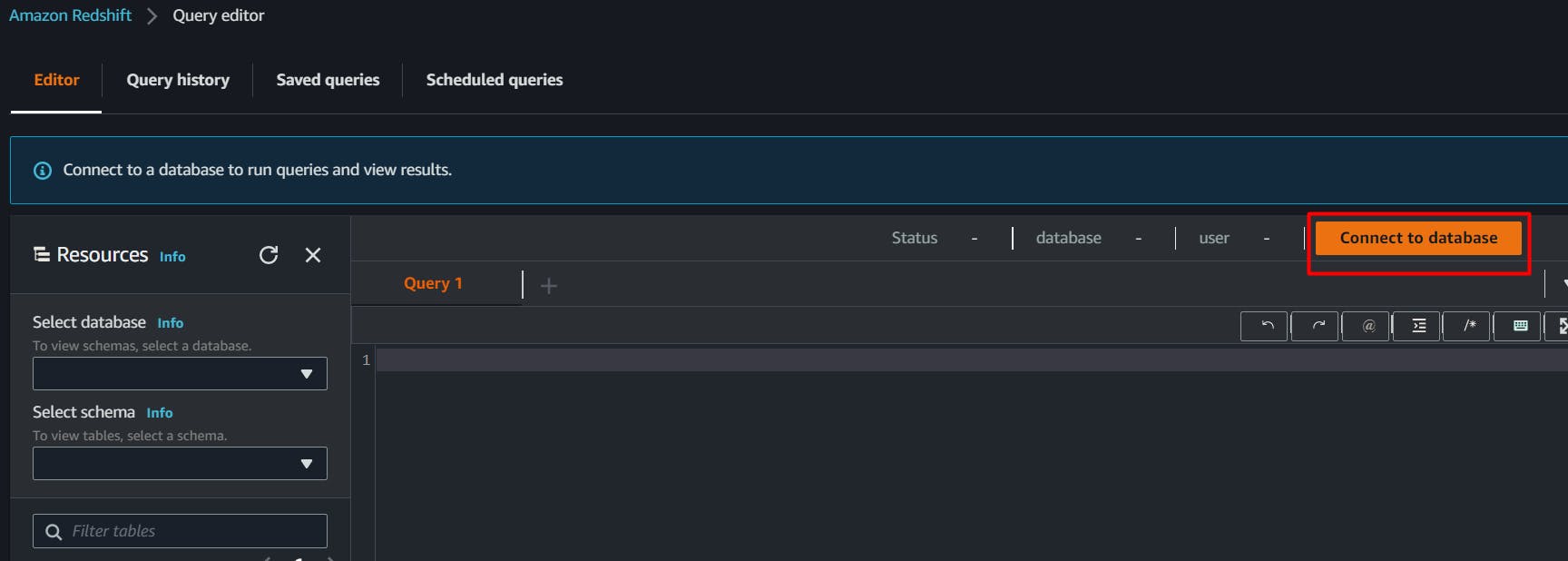
Click on connect database,
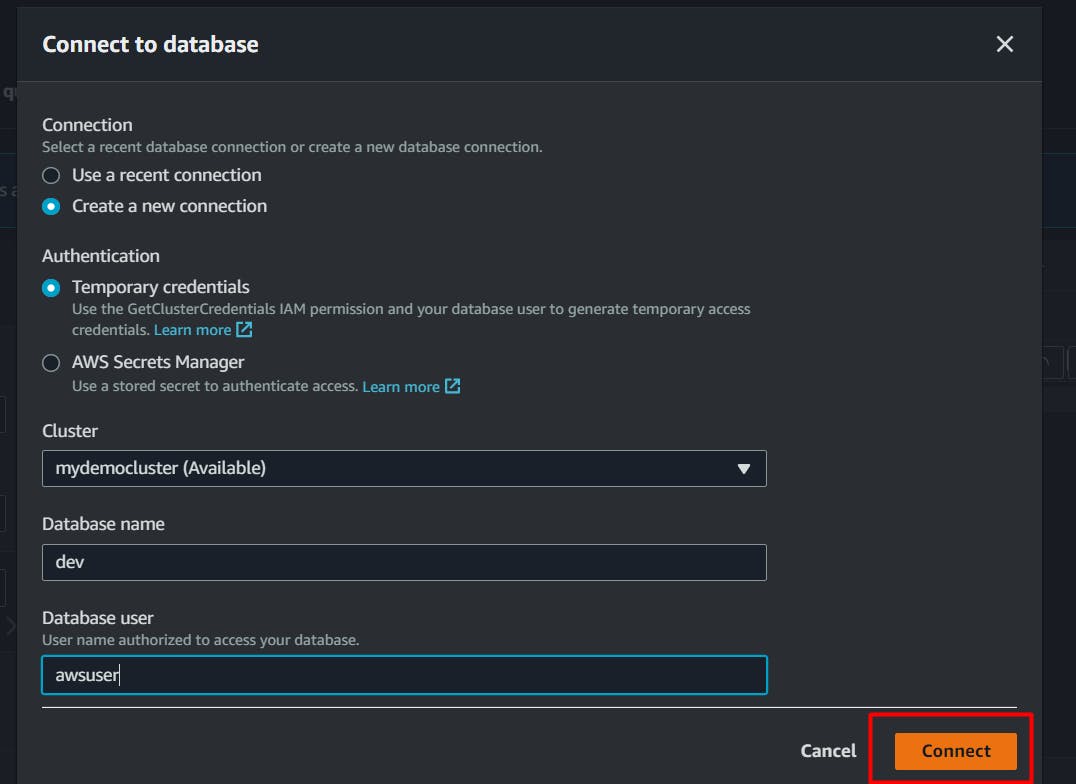
Click on connect,
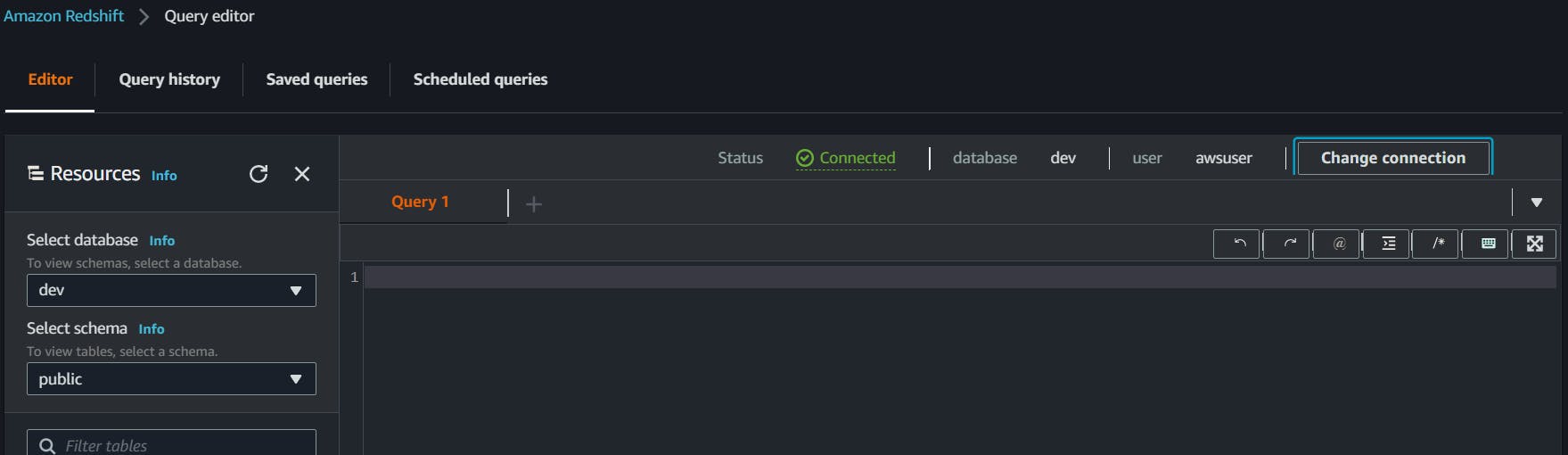
let's run our first query,
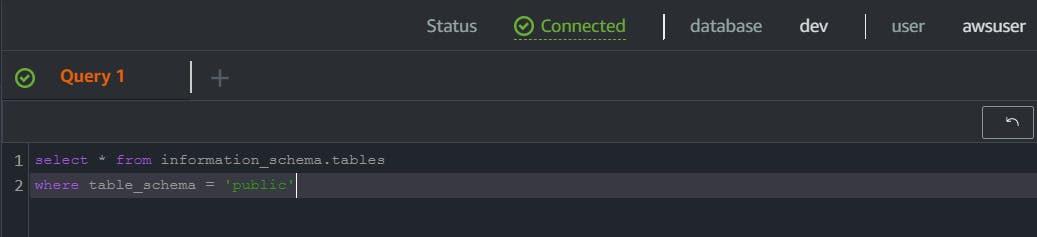
we got the output below, which shows all tables which is in the public schema,
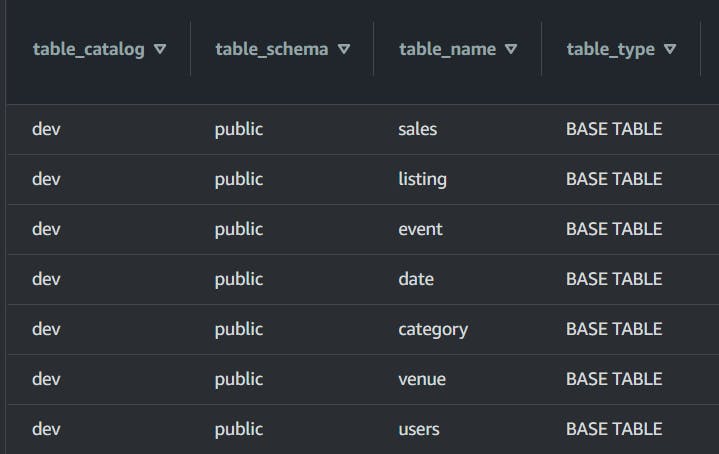
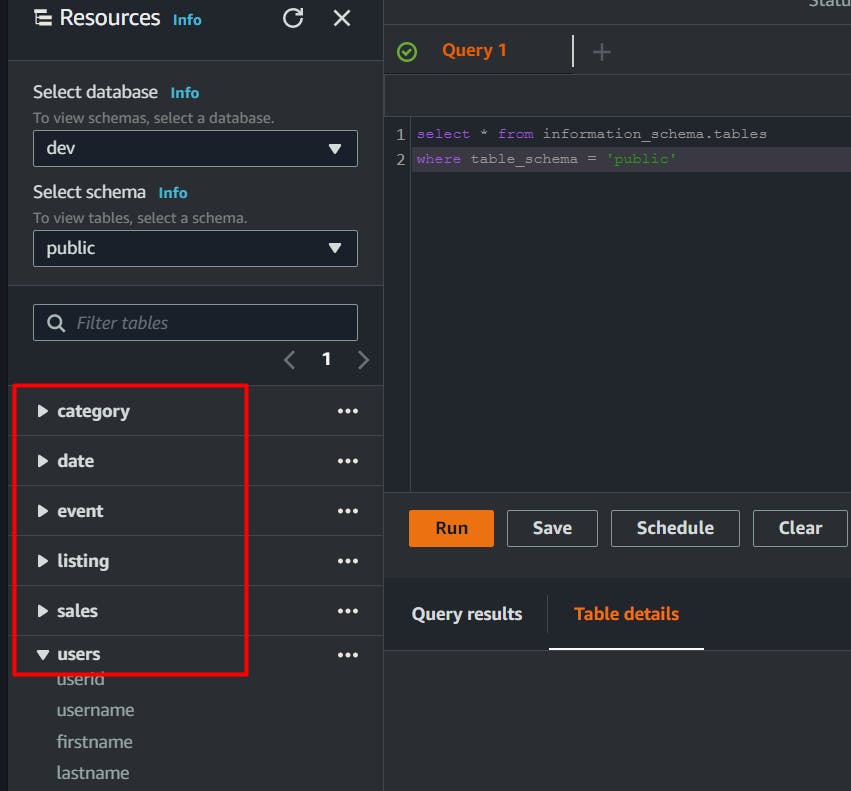
we also list all tables in the public schema in the console,
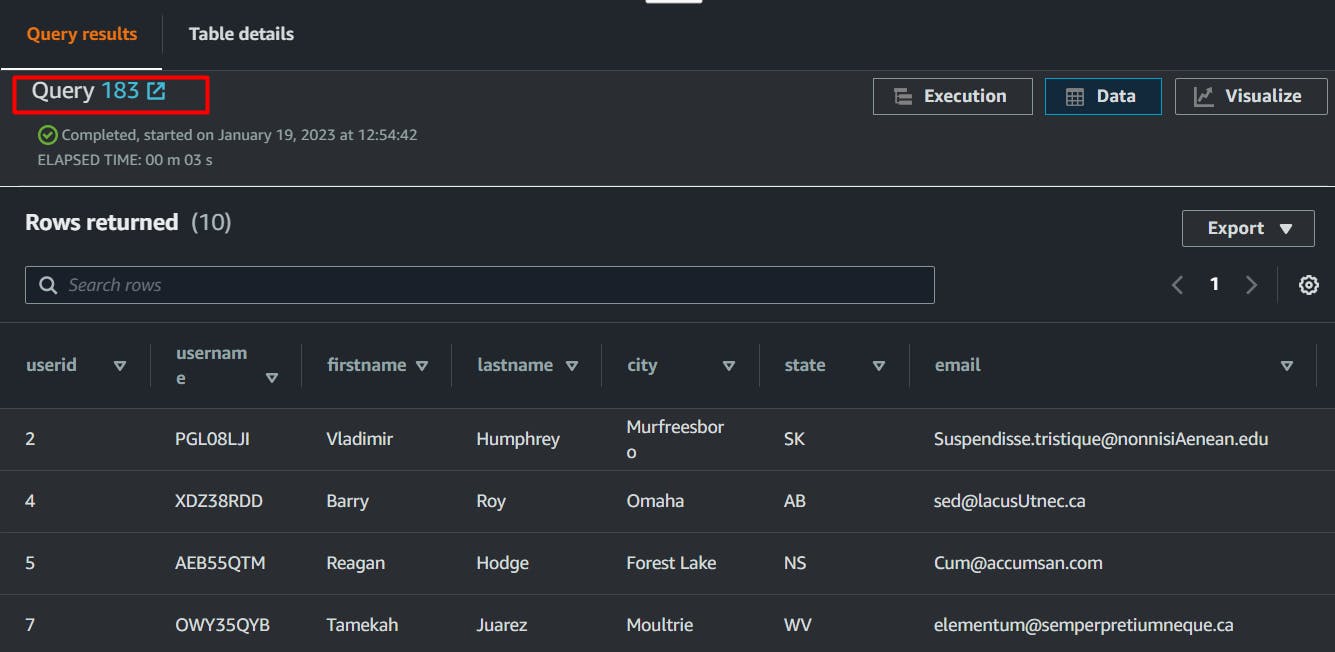
lets query users' table and list values,
select * from users LIMIT 10
select count(*) from users
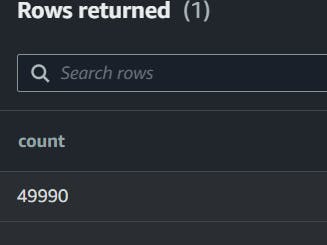
total of 49k entries there...
Create table,
create table myusers (
user_id INT PRIMARY KEY,
user_fname VARCHAR(30),
user_lname VARCHAR(30)
)
Insert data,
insert into myusers (user_id, user_fname, user_lname)
values (1,'Harry','Patel')
let's verify table records,
select * from myusers
output,

similarly, we can do the rest of the operations in the query editor.
let's clean up the redshift cluster,
Click on the delete menu,
we have seen in this article, how to create a redshift cluster and query the database.