





Prerequisite
AWS account
AWS CLI setup in local
redshift cluster created
s3 bucket
Please follow the below link to create a redshift cluster,
setup data into an s3 bucket
download the file in your local system from this link.
Now copy to the s3 bucket,
aws s3 cp part-00000 s3://workshopdemo171222/

create database and user in redshift,
connect query editor in redshift console,
create database,
create database mydb
Now connect created database in the query editor, for that click on change connection,
after change database connection in query editor,
create table myorders (
order_id INT PRIMARY KEY,
order_date DATETIME,
order_customer_id INT,
order_status VARCHAR(30)
)
Create IAM User for copy data from s3 ,
create new iam user with programmatic access only and having s3 full access policy.
after creating go into query editor and run query
COPY myorders from 's3://xxxx/part-00000'
CREDENTIALS 'aws_access_key_id=xxxxx;aws_secret_access_key=xxxxx'
CSV;
Now lets verify data into the table,
select * from myorders limit 10
output is like below,
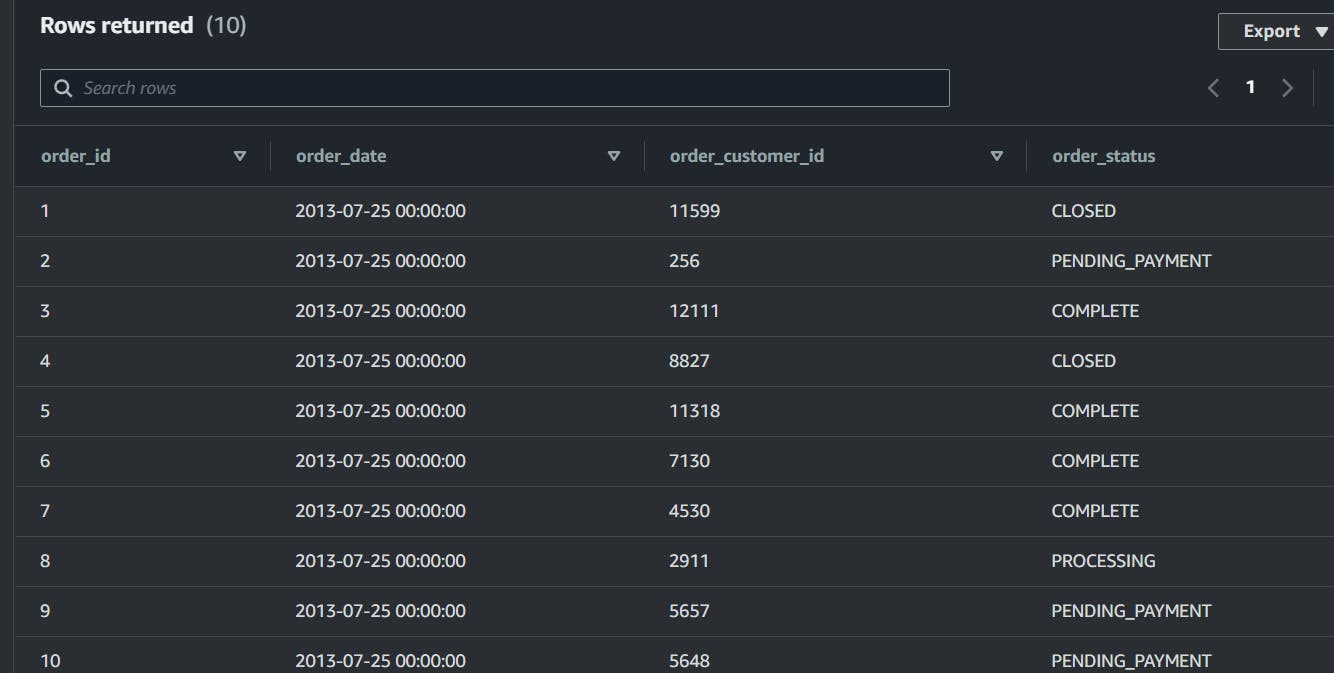
Hence, we have gone through that how we can copy data from s3 bucket to our redshift cluster.
How COPY command work to check in details please check this link.